今天学习如何安装hapood安装
1.安装hapood安装
2.需要的资料
3.开始安装
1.创建目录
mkdir -p /export/server

2.进入目录下
cd /export/server/
3.安装
安装需要的依赖
yum install gcc gcc-c++ make autoconf automake libtool curl lzo-devel zlib-devel openssl openssl-devel ncurses-devel snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst zlib -yyum install -y doxygen cyrus-sasl* saslwrapper-devel*
下载安装cmake-3.9.4
文件下载
wget http://www.cmake.org/files/v3.19/cmake-3.19.4.tar.gz

文件安装
解压文件
tar zxvf cmake-3.19.4.tar.gz
进入目录编译安装
cd /export/server/cmake-3.19.4
安装
./configure这里安装比较慢
继续安装
make && make install

验证是否安装成功
cmake -version
下载安装 snappy
下载
Index of /repo/pkgs/snappy
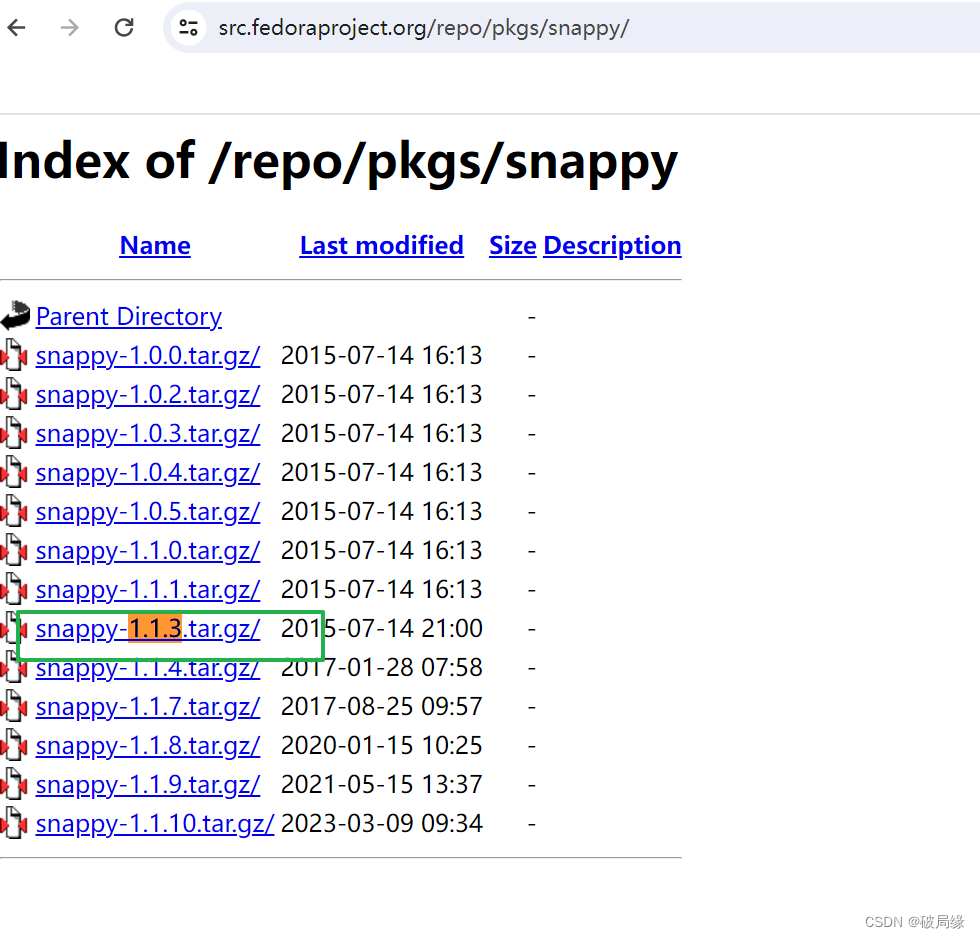
下载 1.1.3的版本
安装
卸载已经安装的
rm -rf /usr/local/lib/libsnappy*rm -rf /lib64/libsnappy*上传文件
上传文件snappy-1.1.3.tar.gz到 /export/server/目录下

解压文件
tar zxvf snappy-1.1.3.tar.gz

安装 编译
cd /export/server/snappy-1.1.3./configure
编译
make && make install
验证
ls -lh /usr/local/lib |grep snappy

安装JDK文件
上传文件
jdk-8u241-linux-x64.tar.gz 到 /export/server/目录下
解压
tar zxvf jdk-8u241-linux-x64.tar.gz
配置环境变量
vim /etc/profile
注意
进入到新的页面中
shift+g 然后输入i 进入编辑模式
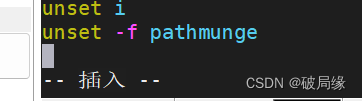
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar加入到
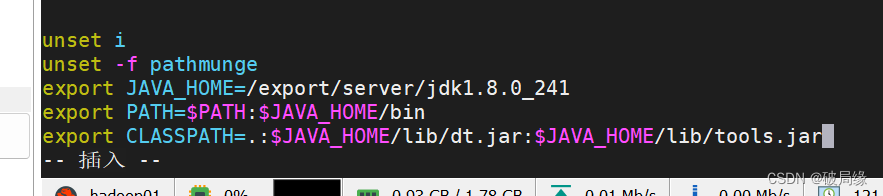
输入 esc 退出 编辑模式
输入 :wq 保存 退出

文件生效
source /etc/profile
验证文件
java -version
安装maven
下载maven
maven下载地址 Index of /maven/maven-3/3.8.8/binaries
绿色的是文件路径
上传文件
解压文件
tar -zxvf apache-maven-3.8.8-bin.tar.gz
配置环境变量
vim /etc/profile
export MAVEN_HOME=/export/server/apache-maven-3.8.8
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH
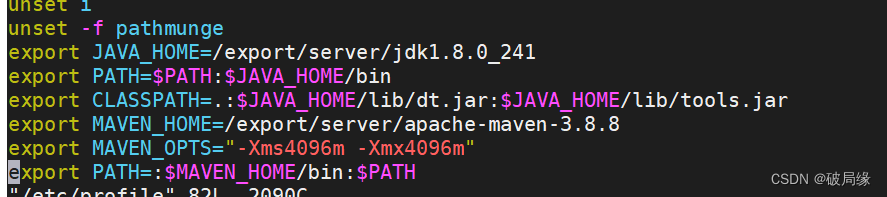
加载文件
source /etc/profile验证文件
mvn -v
配置阿里云地址信息
vim /export/server/apache-maven-3.8.8/conf/settings.xml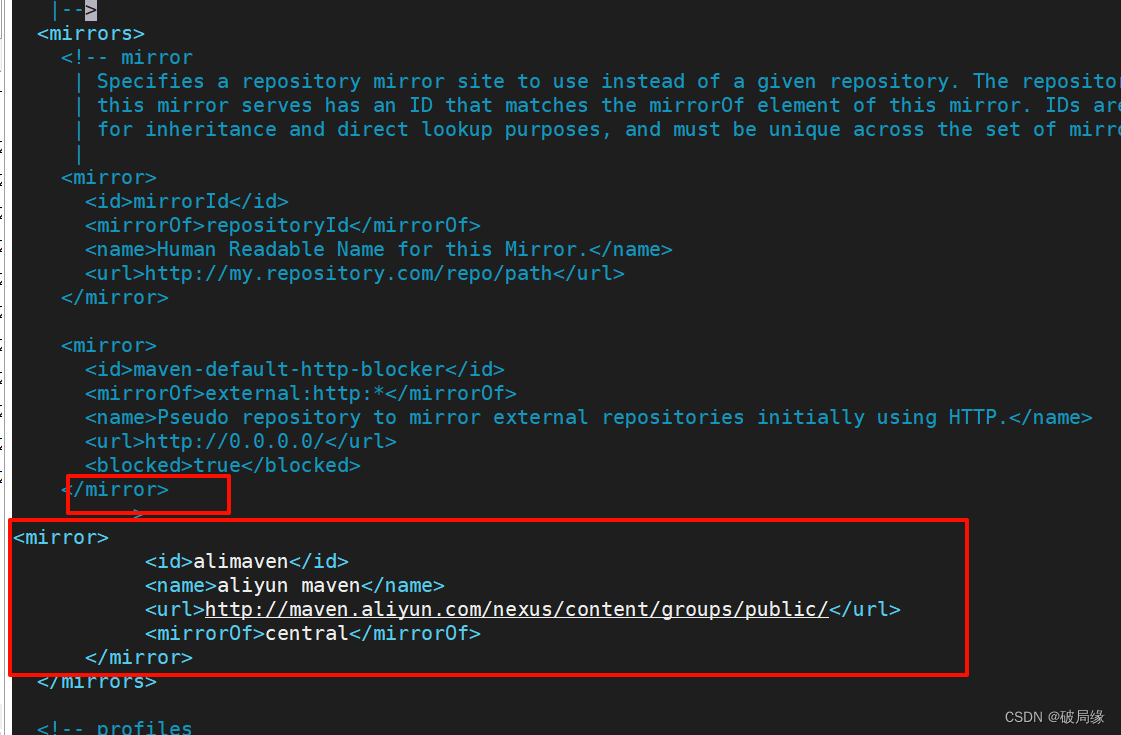
我先在需要加快进度了
安装ProtocolBuffer 3.7.1
下载 ProtocolBuffer 3.7.1文件
GitCode - 开发者的代码家园
上传文件
解压文件
tar -zxvf protobuf-v3.7.1.tar.gz
安装
cd protobuf-v3.7.1/
./autogen.sh
./configuremake && make install验证
protoc --version

安装hadoop
下载hadoop文件信息
链接:https://pan.baidu.com/s/1vmXHrlfd1crbjAwgpZJL5g?pwd=ue6w
提取码:ue6w
上传
注意
必须把文件上传到root目录
解压
tar zxvf hadoop-3.3.0-src.tar.gz编译
cd hadoop-3.3.0
mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
文件说明
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径今天基础环境已经安装完成了明天更新其他的
开始操作三台机器进行安装的方式
1.查看主机名称
cat /etc/hostname2.配置映射关系
vim /etc/hosts
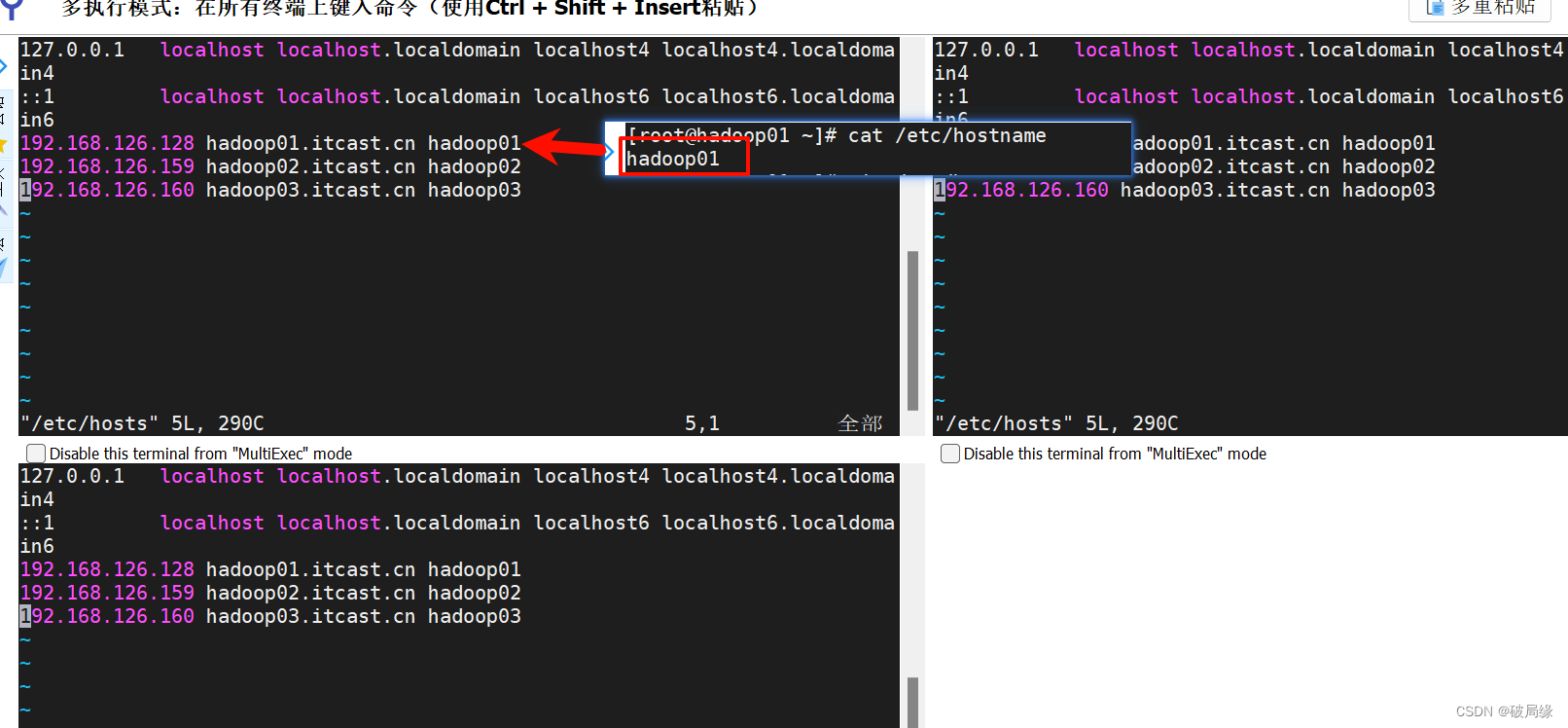
配置的每个主机和ip必须相同才可以使用
3.安装jdk的方式
java -version
上面安装过了我们检测一下
4.同步集群时间
ntpdate ntp5.aliyun.com5.关闭防火墙
1.查看防火墙状态
firewall-cmd --state2.停止防火墙
systemctl stop firewalld.service3.禁止开启自动启动
systemctl disable firewalld.service6.ssh 免密登陆
在hadoop01
生成密钥
ssh-keygen 执行
ssh-copy-id hadoop01
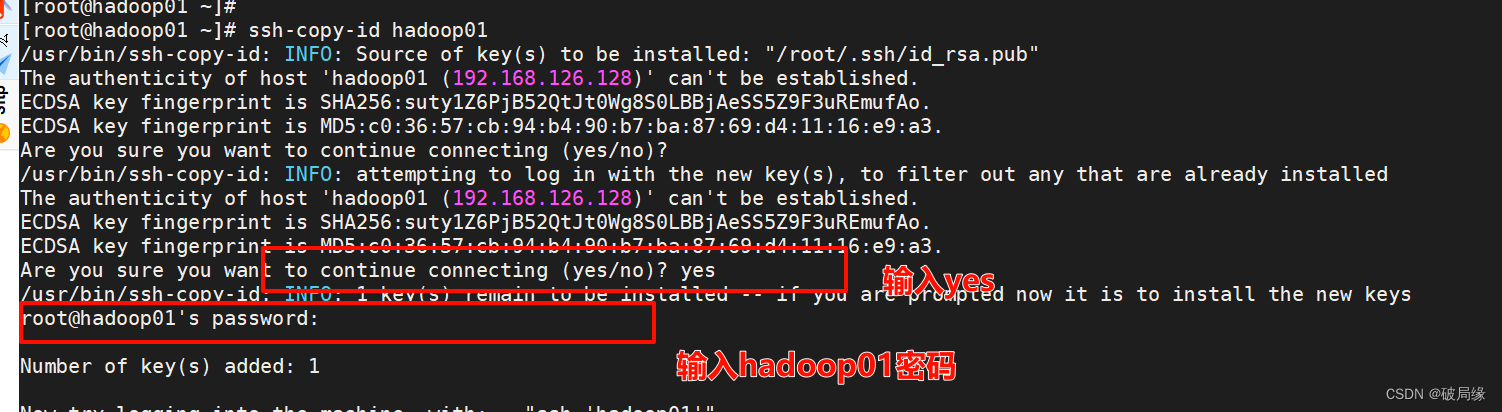
ssh-copy-id hadoop02
ssh-copy-id hadoop03
7.切换目录修改配置文件信息
1.进入目录
cd /export/server
2. 上传文件 hadoop-3.3.0-Centos7-64-with-snappy.tar.gz到/export/server
3.解压文件
tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
4.进入配置文件目录
cd hadoop-3.3.0/etc/hadoop/
5.添加信息
5.1 修改文件 hadoop-env.sh
vim hadoop-env.sh
添加文件
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root 
5.2 修改文件 core-site.xml
vim core-site.xml
添加修改文件
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>5.3 修改配置文件 hdfs-site
修改文件 hdfs-site.xml
vim hdfs-site.xml
添加配置文件
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
</property>
5.4 修改 mapred-site
添加信息
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>5.5 修改 yarn-site.xml
添加配置文件
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
8. 出现了问题
workers

我们是编辑里面信息不是启动
正确操作的方式
vim workers
输入
hadoop01.itcast.cn
hadoop02.itcast.cn
hadoop03.itcast.cn
9.传输文件信息
在 hadoop02, hadoop3执行
mkdir -p /export/server
发送文件
scp -r hadoop-3.3.0 root@hadoop02:$PWD
scp -r hadoop-3.3.0 root@hadoop03:$PWD
10.三台机械添加文件信息
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin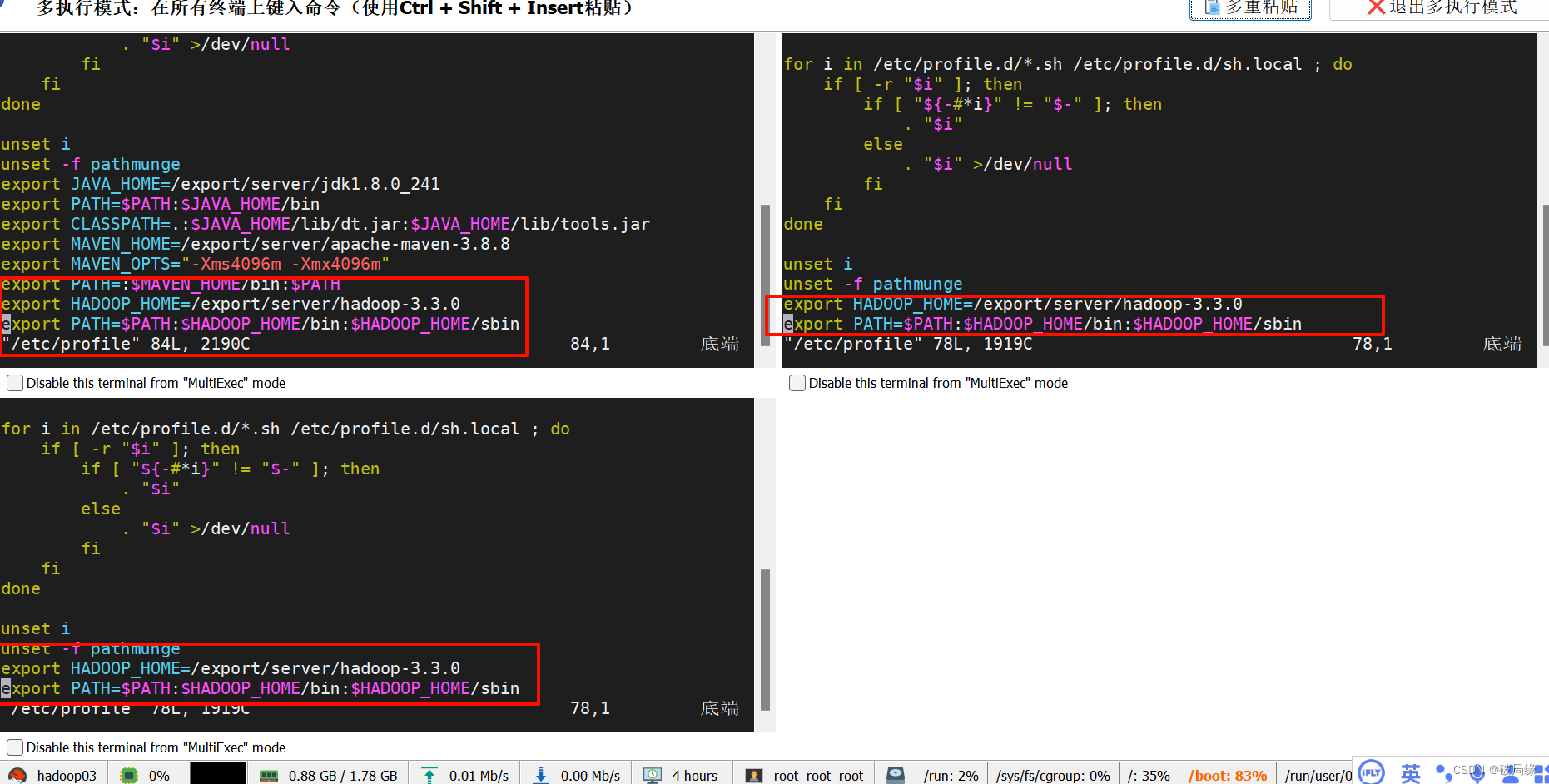
11. 初始化
hdfs namenode -format

启动脚本
start-dfs.sh 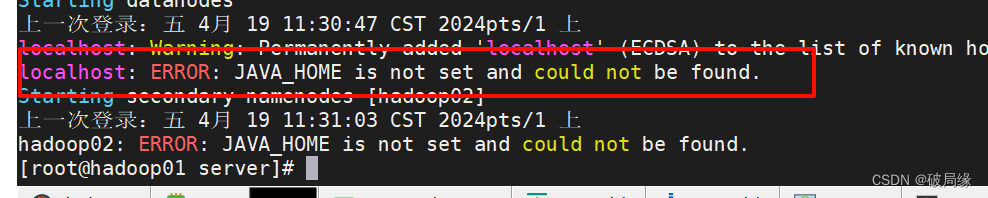
问题这里出现了问题我们没有给其他俩个机器配置java_home 我们配置一下
在hadoop01执行
发送文件
scp -r jdk1.8.0_241 root@hadoop02:$PWD
scp -r jdk1.8.0_241 root@hadoop03:$PWD
配置文件
vim /etc/profile
添加到 hadoop02,hadoop03
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
执行
start-dfs.sh
启动成功
执行
start-yarn.sh 
成功了
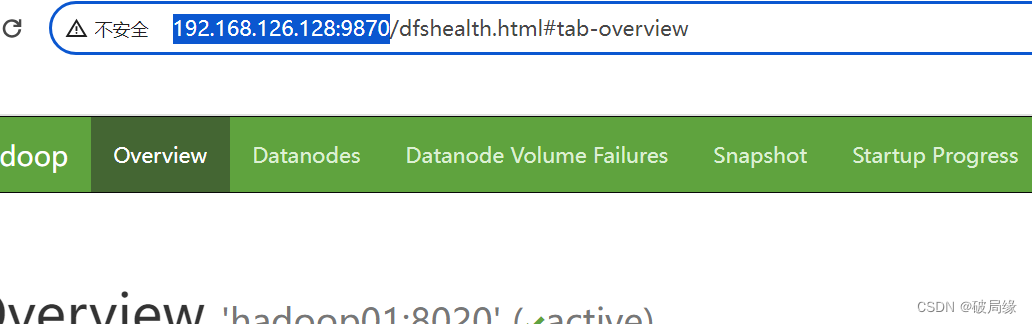
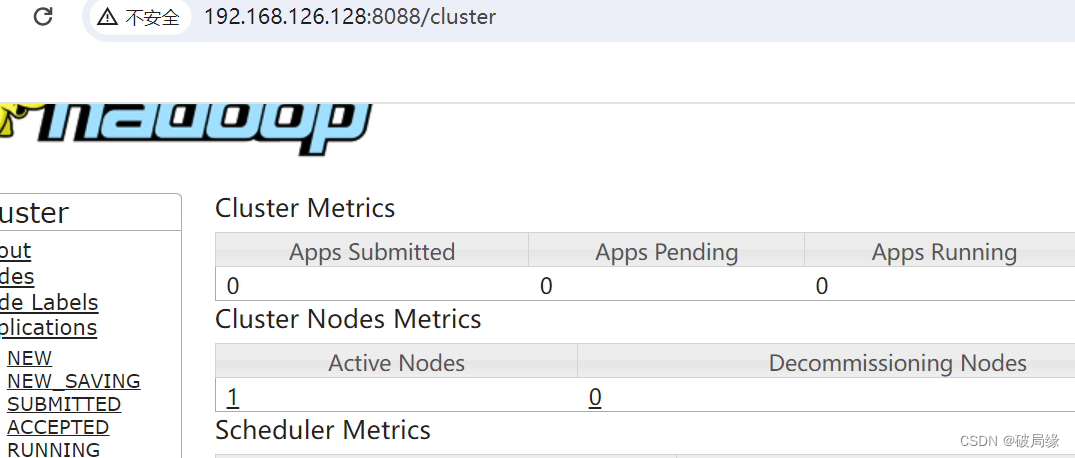
12 输入 jps
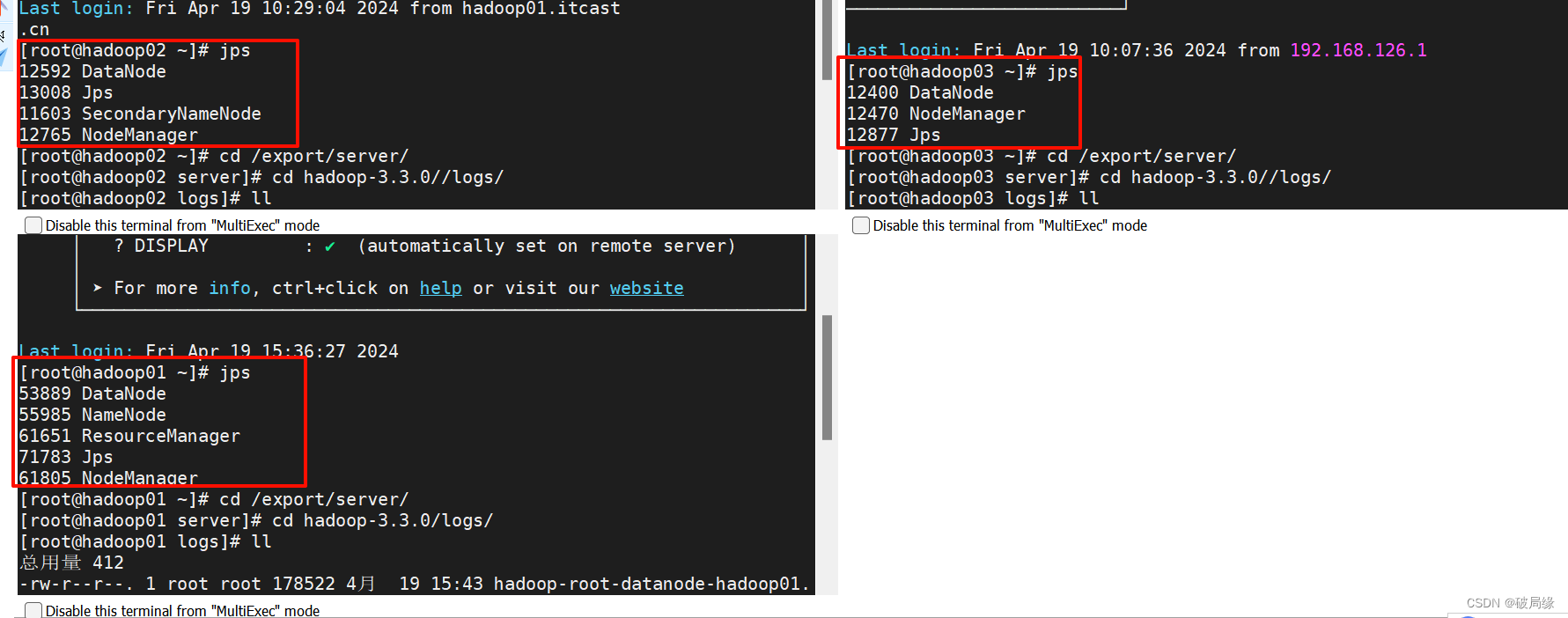
4.需要注意
5.验证结果
6.可能需要的命令
1.查找文件
find / -name CMake-3.19.4
2.shfit+g